One of the biggest concerns enterprise IT teams voice when they see Access Capture, our application packaging and testing automation solution, in action for the first time is the amount of work that needs to be done as a prerequisite.
In reality, however, Access Capture supports multiple deployment possibilities and can utilize most, if not all, of your existing infrastructure. In this article, I want to walk you through the technical prerequisites from an infrastructure point of view. I will tackle application readiness and management prerequisites in another article.
Typical Access Capture Deployment Scenarios
Access Capture provides enterprises and large organizations the ability to automate a variety of application management related processes, such as application discovery, MSI, AppV, and AppStack creation, provisioning of test machines for Quality Assurance (QA) and User Acceptance Testing (UAT) and deployment of applications via SCCM, AppV, or AppVolumes. The product is modular and organizations can buy the entire solution or pick and choose modules to suit their needs.
All Capture modules are designed to be as infrastructure-agnostic as possible and can be deployed using different technologies. Therefore, Access Capture can be deployed in various scenarios. For example, it would be possible to run the Hypervisor API component on Kubernetes, the JobService component as a console application on a Windows Host, and the Administration Web Interface under Internet Information Services (IIS).
To minimize additional workload and investments, we always recommend doing a quick internal infrastructure audit and picking a deployment strategy that best fits their existing infrastructure and requirements.
Technical Requirements For Access Capture
Having said that, here are some recommended pieces of infrastructure — most of which you will already have in house:
SQL Server Or Equivalent Database Server
To deploy Access Capture, you will need a physical or virtual SQL Server or an equivalent database server. While the specifics depend on the size and number of jobs you will be performing, we recommend an SQL Server with 4 CPU Cores, 8GB RAM, and 100GB available disk space to carry out about 50 concurrent jobs. If you are using Microsoft SQL Server, the collation level should be at least 130, for any different database please ensure that your database supports JSON.
There are no specific requirements regarding backup strategies, so please configure your database server according to your organization’s guidelines. However, for optimal performance in a production environment, the database should be mirrored across at least two nodes or the AlwaysOn technology is utilized. You will also need a service account with DBO level access to the Access Capture database which could be created as an empty database by an engineer. The service account can use either Windows Authentication or can be a local SQL account.
RabbitMQ Message Broker
As part of your Access Capture deployment, you will need RabbitMQ, a very popular open source message broker. If you don’t already have an existing RabbitMQ infrastructure in place, we recommend you install it on Kubernetes. This way, fault-tolerant clusters can easily be created. It is a very straight-forward process, but if you need help, Access IT Automation can supply an example .yml file to deploy a new RabbitMQ cluster to Kubernetes using the latest container image hosted on the DockerHub.
If you are already using RabbitMQ, Access Capture can utilize your existing message broker infrastructure if a service account is created that has access to create queues. If possible, it is preferable to have a dedicated virtual host within your RabbitMQ instance to keep queues relating to Access Capture separate from any other queues and to allow the queues to be permissioned correctly.
If installing RabbitMQ on Kubernetes isn’t possible, you can also install RabbitMQ on Windows machines, Linux machines, or within a docker container.
Logstash For Server-Side Data Processing
Next, you will need to install Logstash, an open source, server-side data processing pipeline, which can be installed on Kubernetes (preferred), Linux machines, or Windows machines, or deployed as a docker container. Again, while this is straight-forward, we can provide you with an example .yml file or Docker file to easily get Logstash running on your Kubernetes environment.
If you are already using Logstash infrastructure internally, Access Capture can utilize it as long as you can provide us with a service account equipped with the appropriate permissions (Input, Output, Filter) if authentication is required. In addition, it is recommended that you also install Elastic Search and Kibana for easier processing and visualization of log data.
Consul
The fourth part of infrastructure you need is Consul, a distributed Service Mesh which, ideally, should also be installed on Kubernetes. Also here we can provide you with an example .yml file for faster provisioning of Consul using the latest image from the Docker Hub.
If you are already using Consul for Service Mesh discovery or as a KV store, you can reuse it for your Access Capture installation. Please provide us with a service account if you use authentication.
Guacamole
Lastly, you will need Guacamole, a clientless remote desktop gateway that supports multiple standard protocols such as VNC, RDP, and SSH. If you don’t already have Guacamole in house, we recommend that you install it, as well as the Access Capture Remote Desktop Gateway, on to your Kubernetes infrastructure. For help on installing and updating a component on Kubernetes, please refer to our installation document for detailed, step-by-step instructions.
Hyper-V or VMWare
Because Access Capture utilizes virtual machines, you will need to have access to a Hyper-V or VMWare infrastructure. However, this does not need to be a dedicated instance, as long as it has enough memory and processing power, Access Capture can reuse your existing virtual infrastructure.
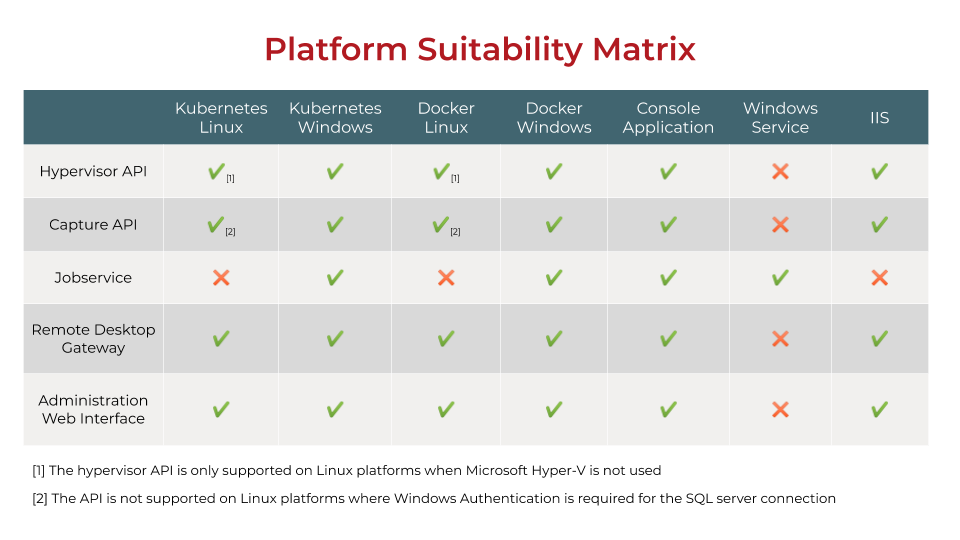
Platform Suitability Matrix
Based on what you already have in house (and therefore what additional components you need), you will need to pick an infrastructure stack that works best for your needs and suits your environment. To make it easier for you, we compiled a platform suitability matrix which outlines all core Access Capture components and the platforms on which they are supported:
Conclusion
As you can see, Access Capture requires no or very little additional infrastructure investment, and the installation and setup efforts are done within minutes. We specifically designed our automation solution to run on proven open source tools or reuse infrastructure most enterprises have in house already to allow you to be up and running as fast as possible and get maximum return on your investment quickly.